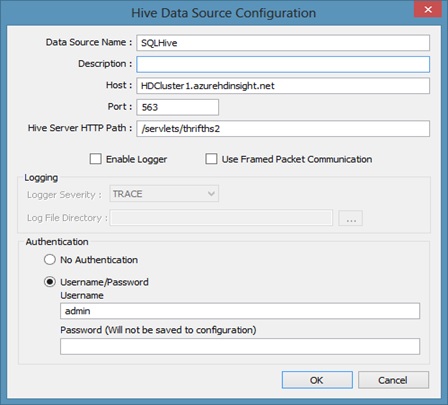
In my previous blog post “Import Hadoop Data into BI Semantic Model Tabular”, I mentioned that you need a SQL Server Linked Server connection to connect SSAS Tabular to a Hive table in Hadoop. That is the case with SSAS Multidimensional instance but in a Tabular instance you can connect directly to Hive table. Thanks to Lara Rubbelke (Technical Architect at Microsoft) who brought to my attention that we can connect a SSAS Tabular project to Hive via HiveODBC connection directly.
After few testing scenarios, we were able to get it to work. Here is how? Running SQL Server Analysis Services 2012 Tabular mode 64-bit on a 64-bit operating system, after creating an SSAS Tabular project using SQL Server Data Tools (SSDT), you have to create both a 32-bit and 64-bit System DSN for this to work. When you create the SSAS import task, you are doing it from SQL Server Data Tools (SSDT), which is a 32-bit process, so it can only see 32-bit DSNs. On a 64-bit operating system, the DSNs are 64-bit by default, so they don’t show up. User DSNs are automatically both 32 and 64bit, so they don’t have this problem. This is a quirk of ODBC and isn’t specific to this driver.
To create a 32-bit DSN, run c:\windows\syswow64\odbcad32.exe and create the System DSN there, and also create an identical one (same name and everything) in the regular 64-bit ODBC Data Source Administrator that is launched from the control panel. When you create the import task from SSDT, it will pick the 32-bit one and then at runtime when the import happens, it will look for the 64-bit one and use it instead. As long as they are identical this is fine.