

Hadoop brings scale and flexibility that don’t exist in the traditional data warehouse. Using Hive as a data warehouse for Hadoop to facilitate easy data summarization, ad-hoc queries, and the analysis of large datasets. Although Hive supports ad-hoc queries for Hadoop through HiveQL, query performance is often prohibitive for even the most common BI scenarios.
A better solution is to bring relevant Hadoop data into SQL Server Analysis Services Tabular model by using HiveQL. Analysis Services can then serve up the data for ad-hoc analysis and reporting. But, there is no direct way to connect an Analysis Services Tabular database to Hadoop. A common workaround is to create a Linked Server in a SQL Server instance using HiveODBC which uses it through OLE DB for ODBC. The HiveODBC driver can be downloaded from here.
Create a Hive ODBC Data Source
The following steps show you how to create a Hive ODBC Data Source.
- Click Start -> Control Panel to launch the Control Panel for Microsoft Windows.
- In the Control Panel, click System and Security->Administrative Tools. Then click Data Sources. This will launch the ODBC Data Source Administrator dialog.

- In the ODBC Data Source Administrator dialog, click the System DSN tab.
- Click Add to add a new data source.
- Click the HIVE driver in the ODBC driver list.

- Click the Finish button. This will launch the Hive Data Source Configuration dialog.
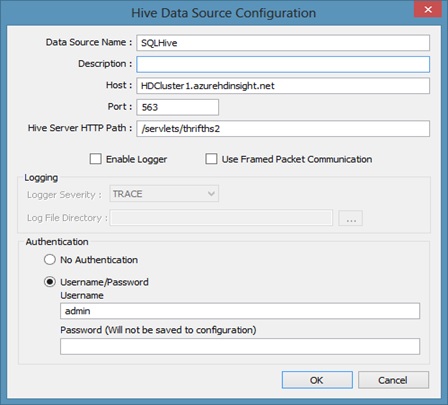
- Enter a data source a name in the Data Source Name box. In this example, SQLHive.
- In this example, we are connecting to HDInsight (Hadoop on Windows Azure). In the Host box, replace the clustername placeholder variable with the actual name of the cluster that you created. For example, if your cluster name is “HDCluster1” then the final value for host should be “HDCluster1.azurehdinsight.net”. Do not change the default port number of 563 or the default value of the Hive Server HTTP Path, /servlets/thrifths2. If you are connecting to Hadoop cluster, the port number would be 10000.
- Click OK to close the ODBC Hive Setup dialog.
Once the HiveODBC driver is installed and created, next you will create a SQL Server Linked Server connection for HiveODBC.
SQL Server can serve as an intermediary and Analysis Server can connect to Hadoop via Hive Linked Server connection in SQL Server, so Hive appears as an OLE DB-based data source to Analysis Services.
The following components need to be configured to establish connectivity between a relational SQL Server instance and the Hadoop/Hive table:
- A system data source name (DSN) “SQLHive” for the Hive ODBC connection that we created in the steps above.
- A linked server object. The Transact-SQL script illustrates how to create a linked server that points to a Hive data source via MSDASQL. The system DSN in this example is called “SQLHive”.
EXEC master.dbo.sp_addlinkedserver
@server = N’SQLHive’, @srvproduct=N’HIVE’,
@provider=N’MSDASQL’, @datasrc=N’SQLHive’,
@provstr=N’Provider=MSDASQL.1;Persist Security Info=True;
User ID=UserName; Password=pa$$word;
Note: Replace the User ID “UserName” and password “pa$$word” with a valid
username and password to connect to Hadoop.
- SQL statement that is based on an OpenQuery Transact-SQL command. The OpenQuery command connects to the data source, runs the query on the target system, and returns the ResultSet to SQL Server. The following Transact-SQL script illustrates how to query a Hive table from SQL Server:
SELECT * FROM OpenQuery(SQLHive, ‘SELECT * FROM HiveTable;’)
Where “HiveTable” is the name of Hadoop Hive table, you can replace the name with the actual Hive table name.
Once the Linked Server is created on the computer running SQL Server, it is straightforward to connect Analysis Services to Hive in SQL Server Data Tools. You can start by creating a new SQL Analysis Services Tabular project
Create a BI Semantic Model Tabular project and connect to a Hadoop Hive table
The steps below describe the way to import data from a hive table into new SSAS Tabular model using the Linked Server connection that you created in the steps above.
To create a new tabular model project
- In SQL Server Data Tools, on the File menu, click New, and then click Project.
- In the New Project dialog box, under Installed Templates, click Business Intelligence, then click Analysis Services, and then click Analysis Services Tabular Project.
- In Name, type Hive Tabular Model, then specify a location for the project files. By default, Solution Name will be the same as the project name, however, you can type a different solution name.
- Click OK.
- In SQL Server Data Tools, click on the Model menu, and then click Import from Data Source. This launches the Table Import Wizard which guides you through setting up a connection to a data source.
- In the Table Import Wizard, under Relational Databases, click Microsoft SQL Server, and then click Next.
- In the Connect to a Microsoft SQL Server Database page, in Friendly Connection Name, type SQLHive DB from SQL.
- In Server name, type the name of the SQL Server database that hosts the SQL Linked Server connection to Hadoop/Hive.
- In the Database name field, click the down arrow and select master, and then click Next.
- In the Impersonation Information page, you need to specify the credentials Analysis Services will use to connect to the data source when importing and processing data. Verify Specific Windows user name and password is selected, and then in User Name and Password, enter your Windows logon credentials, and then click Next.
- In the Choose How to Import the Data page, verify write a query that will specify the data to import is selected. Rename the query name to friendly name and in the SQL Statement window, type the following: SELECT * FROM OpenQuery (SQLHive, ‘SELECT * FROM HiveTable;’)
- And then click Finish.
- Once the above table was imported, you can import additional dimensions and you can create a relationships between the tables.
- Now the Model is ready to be deployed to SQL Server Analysis Services (SSAS) Tabular instance.
The Hive ODBC driver makes it easy to import data from your Hadoop Hive table into SQL Server Analysis Services Tabular instance database where Business Intelligence tools may be used to view and analyze the data.

Reblogged this on Denny Lee and commented:
Great step-by-step for getting data from Hadoop to Analysis Services Tabular.
Pingback: SSAS Tabular using HiveODBC connection | Ayad Shammout's SQL & BI Blog
Pingback: Quick Tips and Q&A for SQL Server Analysis Services to Hive | Denny Lee
Hi, where do I get the Host value for the Hive Data Source Configuration in step 6? My Hive is deployed on a ubuntu machine. Is it the IP address of the machine? Thank you
It is the Hadoop cluster name or IP address. In your case, it is your machine name or IP address. Please read step 8 as you need to make sure you are using the correct port number.
Thanks,
Ayad
Hi Ayad,
Thank you for the quick reply. I’ve tried using either IP or machine name. Port i have left it as 563. However, when I tried to test the connection after creating the link server in MSSQL, it returned this error msg
“Data source name not found and no default driver specified”. (Microsoft SQL Server, Error:7303)
I’ve looked up on this error msg online and most commented that it is due to wrong data source name.
But I’ve already used the same name i’ve created in step 8, much like your example above “SQLHive”.
Hope you can shed some light. Thank you
Regards
Koh
Hi Koh,
Are you running SQL Server 32 or 64 bit? You can ignore the SQL Linked Server step and use SQL Data Tools to connect to Hive in Hadoop directly. Please read my blog on how to use HiveODBC in SSAS Tabular project https://ayadshammout.com/2013/07/13/ssas-tabular-using-hiveodbc-connection
HTH!
Ayad
Hi Ayad,
Sorry because i’m new to this hadoop ecosystem.
This is still concerning the steps above.
Correct me if I’m wrong, that for the link server to work, I have to start the Hive service with this command
$./hive –service hiveserver -p 563
I’ll see this with netstat
tcp 0.0.0.0:563 LISTEN
And if so, do I have to state the port explicitly? or Just leave it as ./hive –service hiveserver. This will cause it to listen at port 10000
Thank you
Koh
Hi Ayad,
Sorry i left this out in the earlier message. I’m running SQL server 2008 64bit
Thank you
Koh
Hi Ayad,
I was able to set up successfully the linked server using another driver from MapR.
However, I’ll like to know if I can do insert statements as well using openquery?
I’ve tried a sample query like this:
insert into openquery(HIVEDW,’select col1, col2 from tableB;’)
select * from openquery(HIVEDW,’select col1, col2 from tableA;’)
But i get this error msg returned:
The requested operation could not be performed because OLE DB provider “MSDASQL” for linked server “HIVEDW” does not support the required transaction interface.
I researched online and i found there were mentions that Hive does not support transactions.
Is this true or have I missed out some configurations?
Thank you
Koh
Pingback: Hive insert with openquery - dBforums
You have made some good points there. I checked on the internet for additional information about the issue
and found most individuals will go along with your views on this website.