In a previous post, I explained how to use RANKX function to calculate revenue ranking for each provider in each department. In this post I’m going to explain how to rank at different levels.
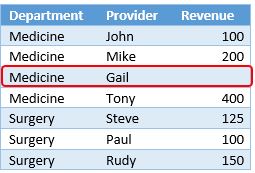
I’m using my previous example which is a list of providers in different hospital clinical departments, I want to rank department and rank providers in each department by revenue (two ranking levels). Here is my sample table I started with creating a table in Excel “Table1” and add it to Power Pivot model.

I created following measures to rank provider by revenue:
TotalRevenue:=SUM(Table1[Revenue])
Rank:=RANKX(All(Table1[Provider]),[TotalRevenue],,,Dense)
The Rank measure will rank the [TotalRevenue] for the current Row against the [TotalRevenue] for all other rows in the Revenue column. The ALL(Table1[Provider]) is the list of values that the rank function use to compare the current row against. Since I used ALL function to ignore Provider filter context, I will get the following:

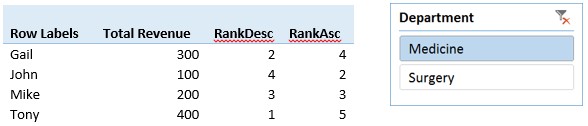
Now let’s add the department to pivot table and see how Rank measure works:

As you can see the Rank by provider still working within each department by the rank by department is not, it uses the department total and compare it against list of provider values. I want to rank each department against all departments, and rank providers within each department. In order to do that in Power Pivot, I want to create an IsDepartmentLevel measure that will return TRUE if the current selection in the PivotTable has a valid correspondent department definition, FALSE otherwise. If it is TRUE, Rank department, otherwise Rank providers. Let’s see how to write the IsDepartmentLevel measure:
IsDeptartmentLevel:=(
COUNTROWS(Table1)
=
CALCULATE(COUNTROWS(Table1) ,
ALL(Table1),
VALUES(Table1[Department])
)
)
The IsDepartmentLevel measure checks that the number of rows that are active in Table1 equal to the number of rows that would be active by removing from the filter context any column except Department.
As you can see in the following Pivot table, I added the IsDepartmentLevel measure to Pivot table, the IsDepartmentLevel measure is FALSE for every provider level but TRUE for department.

Now we are able to identify the department level which we need in order to evaluate the Rank measure and Rank department vs. provider.
Let’s re-write the Rank measure and see how to use the IsDepartmentLevel measure and RANKX function to rank departments and providers by revenue.
Rank:= IF(
[IsDeptartmentLevel],
RANKX(Filter(All(Table1[Department]), [TotalRevenue]),[TotalRevenue],,,Dense),
RANKX(Filter(All(Table1[Provider]), [TotalRevenue]),[TotalRevenue],,,Dense)
)
I used IF function to evaluate IsDepartmentLevel measure, if it is TRUE, it will calculate the revenue ranking for each department, otherwise it will calculate the revenue ranking for each provider.
The following Pivot table shows the ranking for each department.

When I expand the departments, it shows the ranking for each provider in each department and maintained the ranking for each department.

In this post, you have seen how to use RANKX function and calculate at different levels (department and provider) using one measure.